VideoCLIP
VLM(Visual Language Model)의 관심이 높아지고 있다. 특히 CLIP 모델의 성공으로 인해 대조학습이 VLM 모델의 대표적인 하나의 학습방법으로 자리잡고 있다.
CLIP의 성공으로 인해, 이미지와 텍스트의 의미 공간을 동일한 임베딩 공간에서 정렬(alignment)하는 대조학습(contrastive learning) 방식이 VLM 학습의 대표적 패러다임으로 자리잡았다.
해당 방법론들을 비디오 데이터에도 사용하려는 시도가 많이 나타나고 있으며, 그 중 대표적인 논문이 VideoCLIP이다.
모델 구조
- Video Encodr : 시간적 연속성과 공간적 구조를 동시에 포착하기 위해 3D ConvNet(S3D 등)을 사용하여 프레임 시퀀스에서 시공간적 특징을 추출함.
- Text Encoder : BERT 기반 Transformer
주요 아이디어
VideoCLIP은 비디오를 일정 구간(clip)으로 분할하여 프레임 단위 특징을 추출한 뒤, 이를 temporal average pooling 또는 Transformer를 통해 시공간적으로 압축하고, 문장 임베딩과 함께 공통 임베딩 공간에서 대조학습(contrastive learning)을 수행한다. 이를 통해 텍스트와 비디오 간 의미적 대응 관계를 학습하고, zero-shot retrieval이 가능해진다.
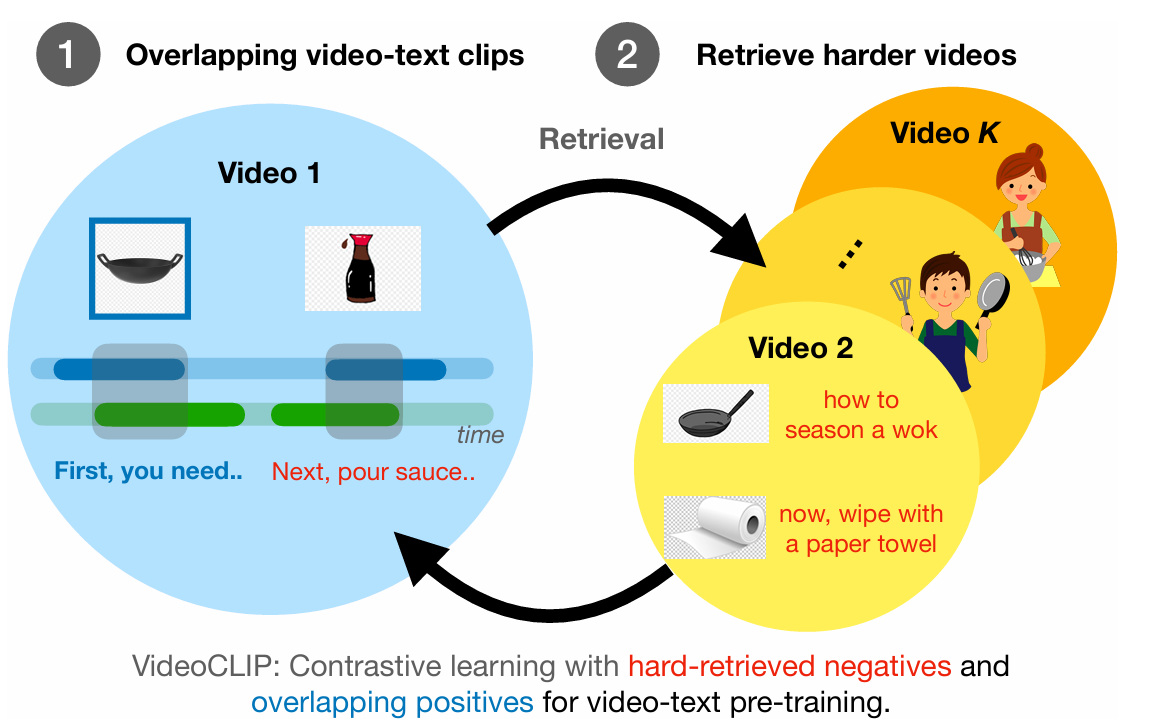
Temporal Overlap
- VideoCLIP은 자막(또는 내레이션)의 시간 정보를 이용해 클립-문장 쌍을 구성하지만, 클립의 시간 경계와 문장의 구간이 완전히 일치하지 않는 경우가 많다. 따라서, temporal overlap(시간적 겹침)을 기준으로 클립과 문장을 매핑하여, 하나의 클립이 여러 문장과 연관될 수 있도록 하여 불완전한 시간 정렬 문제를 완화한다.
Hard Negative Mining
- Hard Negative Mining은 단순히 랜덤한 다른 영상-문장 쌍이 아닌, 의미적으로 유사하지만 다른 문장(near-miss negatives)을 부정 예시로 사용한다. 이를 통해 모델이 세밀한 의미 차이를 구분하는 능력(fine-grained discrimination)을 학습하게 되어, 표현 학습의 품질이 크게 향상된다.
정리
- VideoCLIP 논문은 CLIP 철학을 이미지에서 비디오 데이터로 확장한 최초 대규모 constrastive pretraining 적용하였고, Temporal Overlap 기반의 weakly aligned 데이터 학습 방법을 제시하였다. 여기에 Hard Negative Mining 기법을 통해 세밀한 의미 구분 능력을 개선하여 이후 비디오-언어 학습 연구의 토대를 마련하였다.
This post is licensed under CC BY 4.0 by the author.