Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
1. 배경
CLIP과 같은 VLP (Vision-Language Pretrained Model) 은
대규모 이미지-텍스트 쌍을 학습하여 강력한 Zero-Shot 분류 성능을 보여준다.
하지만 여전히 Downstream Task에서 Fine-Tuning 없이 바로 활용하기에는 한계가 존재한다.
이를 해결하기 위해 다양한 접근법들이 제안되었다.
Downstream Task 활용 방식
- Full Fine-Tuning
성능은 우수하지만 시간 및 자원 소모가 큼 - Adapter
가벼운 Fine-Tuning 방식이지만 여전히 학습 필요 - Prompt Tuning
Text side에서 일부 개선 가능하나 한계 존재
👉 오늘 소개할 Tip-Adapter는
Few-shot 데이터로 학습을 하지 않고도 성능을 개선할 수 있는 방법이다.
비용이 적게 들면서도 효율성이 뛰어나 현업 적용에 적합하다.
2. 주요 아이디어
Tip-Adapter의 핵심 아이디어
- CLIP의 Image Encoder로 Few-Shot Training Set 임베딩 → Cache 구축
- Key = 이미지 feature
- Value = 라벨 one-hot vector
- 추론 시, Test 이미지의 feature와 Cache Key들의 유사도 계산
- Cache 기반 예측과 CLIP Zero-shot 예측을 결합하여 최종 결과 산출
CLIP-Adapter vs Tip-Adapter
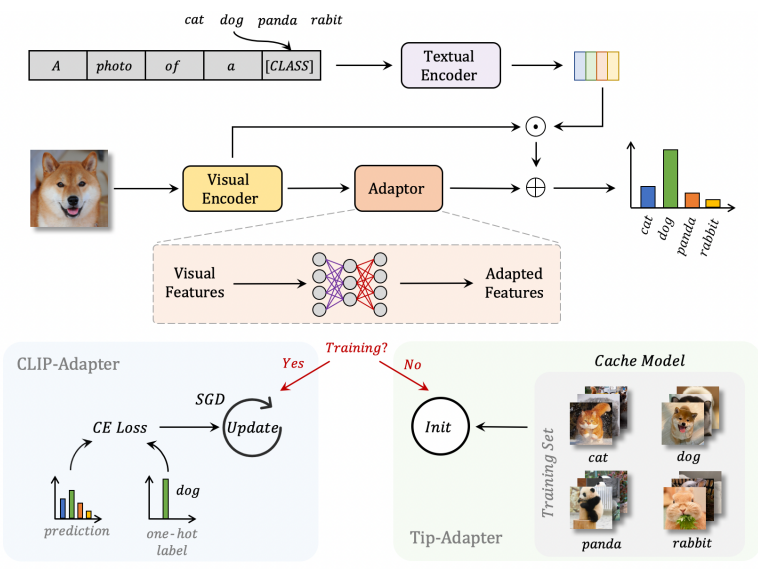
- 좌측 (CLIP-Adapter)
- 작은 모듈을 Few-shot 데이터로 학습(Training) → 성능 개선
- 우측 (Tip-Adapter)
- 작은 모듈을 학습하지 않고 초기화(Init)만 수행
- 이후 Cache Key들과 유사도 계산을 통해 Value(라벨) 활용
➡️ 핵심 차이점은 “학습 유/무”
즉, CLIP-Adapter는 학습이 필요하지만, Tip-Adapter는 Cache Init만으로도 성능 개선 가능하다.
3. 전체 추론 과정
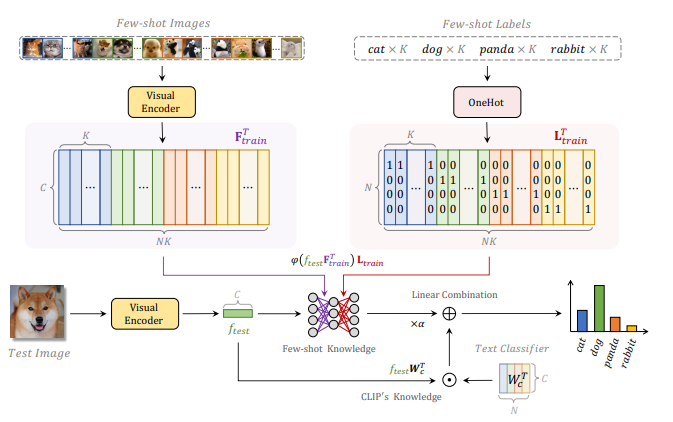
- Few-shot 데이터를 이용해 Cache 생성
- Test 이미지 입력
- CLIP Knowledge (Zero-shot)
- Cache Knowledge (Few-shot 기반)
- 두 예측 값을 선형 결합하여 최종 분류
- 결합 비율은 하이퍼파라미터 α로 조절
4. 시사점
✅ Fine-Tuning의 대안 제시
- 학습 없이도 Downstream Task 성능을 개선할 수 있음을 보여줌
✅ Non-parametric 접근의 부활
- 전통적인 캐시/메모리 기반 방법이 VLP와 결합되며 다시 중요해짐
✅ 효율성과 실용성
- 리소스가 부족한 연구자·개발자에게 매력적인 접근법
- CLIP을 현업에서 손쉽게 활용할 수 있는 실질적 방법 중 하나
This post is licensed under CC BY 4.0 by the author.