CLIP-Adapter : Better Vision-Language Models with Feature Adapters
최근 VLM(Vision-Language Model) 모델을 단순히 사용하는 것 뿐만 아니라 다양한 학습 방법들에 대해서 연구되고 있다. 오늘은 그 중 소량의 데이터셋으로 CLIP 모델을 학습할 수 있는 방법을 소개한 CLIP-Adapter 논문에 대해서 소개하겠다.
1. 개요
CLIP 은 대규모 이미지-텍스트 쌍으로 학습되어 우수한 zero-shot 분류 성능을 가지고 있다. 하지만 DownStrem Task에서는 프롬프트 엔지니어링이라는 번거로운 작업에 대한 의존도가 매우 높다.
- DownStream Task - 해당 모델을 실제 활용할 수 있는 Task들을 의미함 ex) 분류, 인식
이러한 문제점들을 해결하기 위해 다양한 방법들이 연구되어져 왔다. 대표적으로는 CoOp 라는 논문이 있는데 해당 논문에 대해서도 다음에 소개하겠다.
간단히 설명하면 프롬프트의 핵십 keyword 들을 학습가능한 가중치로 나타내어 해당 작업에 가장 적합한 프롬프트를 찾아내는 것을 방법으로 번거로운 프롬프트 엔지니어링을 완화한 것이다.
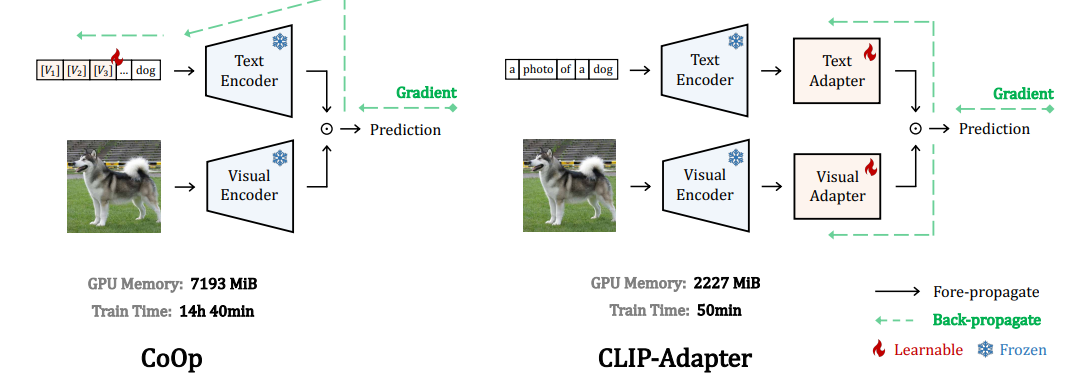
하지만 여전히 한계점이 존재하였는데, CoOp는 텍스트 인코더에만 적용되는 방법이라는 것이다.
그리하여 해당 논문에서는 프롬프트를 컨트롤 하는 것이 아닌 작은 Adapter 모듈을 이미지 인코더, 텍스트 인코더 모두에 결합하여 few-shot 학습에 활용한다.
즉, CLIP 파라미터는 동결하여 과적합을 방지하고 적은 데이터로도 학습이 가능하게끔 해준다.
- 기존 CLIP의 표현력을 유지 + 작은 데이터셋으로 새로운 task에 적용 가능
2. 주요 내용
CLIP-Adapter Idea
- 어뎁터는 이미지 인코더 , 텍스트 인코터에 선택적으로 추가 가능
- 출력은 원래 CLIP의 특징과 어뎁ㅌ처가 만든 새로운 특징을 잔차 방식으로 섞어서 사용
- 섞는 비율(α, β) : 고정값 또는 학습 가능한 파라미터로 선정 가능
적용 방식
- 이미지 특징 추출: CLIP 비전 인코더로 이미지 임베딩 생성 -> f
- 텍스트 임베딩 생성 : 클래스 이름을 하드 프름프트에 넣고 텍스트 인코더로 임베딩 생성 -> W
- 어뎁터
- Visual Adapter: f를 bottlenect 구조로 변환해 보정 특징 생성
- Text Adapter: W를 병목 구조로 변환해 보정 특징 생성
- Residual 혼합
- 최종 이미지 특징 : (1-α)f + α보정_f
- 최종 텍스트 특징 : (1-β)W + β보정_W
- 분류 : 각 특징 내적 후 Softmax로 확률 계산.
추가 분석
- Residual 비율 α, β:
- 도메인 차이가 큰 데이터셋 -> α, β 높게
- 일반 도메인 -> α, β 낮게
- 어댑터 삽입 위치:
- 마지막 단에 넣는 것이 가장 효율적
3. Insight
✅ CLIP 활용을 더 실용적으로 만든 접근 - 프롬프트 기반의 한계를 벗어남
✅ Parameter-efficient 방법의 좋은 예시 - 효율적 학습 방법 제안
✅ 실전에서도 유용한 효율성 - 학습 시간이 짧음, 추론 속도 빠름, GPU 메모리 자원 적게 사용