BLIP : Bootstrapping Language-Image Pre-training
최근 VLM(Vision-Language Model)에 대한 연구가 늘어나고, 실제 활용도가 높아지고 있다. 대표적으로 유명한 논문인 CLIP과 BLIP이 있는데 오늘은 BLIP에 대해서 알아보도록 하겠다.
1. 개요
BLIP은 Vision-Language-Pre-training에서 “이해(Understanding)” 과제와 “생성(Generation)” 과제를 동시에 잘 수행할 수 있도록 모델 측면에서는 MED : Multimodal Mixture of Encoder-Decoder 와 데이터 측면의 CapFilt : Captioning & Filtering 기법을 이용하였다.
이해와 생성은 다음과 같은 것을 의미한다.
- 이해(Understanding) : 이미지와 텍스트간의 관계를 파악하고 그에 맞는 답을 찾을 수 있음
- 생성(Generation) : 이미지 정보를 바탕으로 적절한 텍스트를 생성할 수 있음
2. 주요 기법
Multimodal Mixture of Encoder-Decoder(MED)
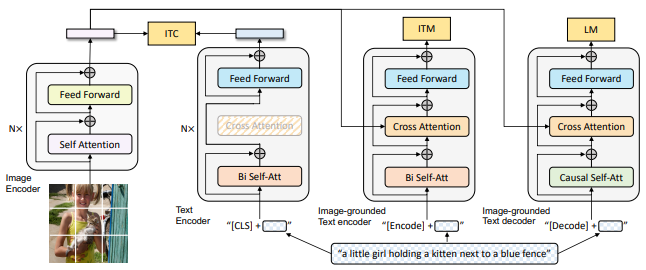
- 위 모델로 아래 3가지 기능을 모두 수행할 수 있음
- Unimodal Encoder + ITC(Contrastive Learning)
- Image-Grounded Text Encoder + ITM (Image–Text Matching)
- Image-Grounded Text Decoder + LM
- 각 기능별 모듈 및 어텐션 구조는 아래와 같다.
- Unimodal Encoder
- 모듈 : 이미지 : ViT / 텍스트 : BERT
- 어테션 구조 : Bi-Self-Attention
- Loss : ITC(InfoNCE)
- Image-Grounded Text Encoder
- 모듈 : Text Encoder + Cross-Attention
- 어테션 구조 : Bi-Self-Attention + Cross-Attention
- Loss : ITM(Binary CE)
- Image-Grounded Text Decoder
- 모듈 : Text Decoder + Cross-Attention
- 어텐션 구조 : Causal Self-Attention + Cross-Attention
- Loss : LM(Token CE)
- Unimodal Encoder
- 각 기능별 역할 및 순서
- Unimodal Encoder 는 이미지 와 텍스트 임베딩을 동일 공간에 정렬
- Text Encoder -> Cross-Attention 으로 이미지 정보 융합하여 매칭 분류
- Decoder는 Autoregressive 생성을 위해 미래 토큰이 마스킹된 Causal Self-Attention 사용
- Loss 역할
- ITC의 InfoNCE : 이미지 - 텍스트 대조 학습에서 postive 쌍의 유사도는 키우고, negatice 쌍의 유사도는 낮추는 역할
- ITM의 Binary CE : 이미지 - 텍스트 쌍이 True 인지 False 인지 이진 분류
- LM의 Token CE : 이미지 조건부 문장 생성에서 “다음 단어”를 올바르게 예측
- 파라미터 공유를 통해 모델 크기와 학습 시간을 감소시키고 multi-task 시너지를 강화시킴
- 파라미터 공유 : 임베딩, Cross-Attention, Feed-Forward
- 파라미터 비공유 : Self-Attention 레이어
- 위 모델로 아래 3가지 기능을 모두 수행할 수 있음
Captioning & Filtering(CapFilt)
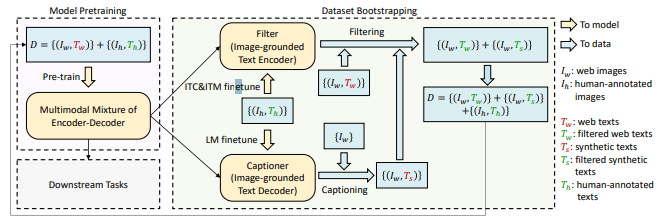
Captioner 와 Filter를 이용하여 노이즈가 많은 웹 데이터를 효과적으로 재활용하여 레이블링 비용 없이 대규모 학습 데이터를 확보함
- Captioner : 웹 이미지에 synthetic 캡션 생성
- Filter : 생성 캡션과 원문 캡션 모두에 ITM 판별기를 적용해 부적합 캡션을 제거함
논문 제목에 Bootstrapping 이라는 용어가 들어가 있는데 AI모델 분야에서는 ~를 바탕으로 해 더 좋은 방법 및 모델을 개발 및 생성할 때 사용한다.
해당 용어가 사용된 이유를 CapFilt 를 통해 설명하면 다음과 같다.
- Captioner : COCO 데이터로 LM 모델을 파인튜닝하여 웹 이미지에 대한 synthetic 캡션을 생성
- Filter
- Image-Grounded Text Encoder 내부에 위치함
- COCO로 ITC+ITM을 파인 튜닝 하여 웹 원문과 합성 캡션 모두에 적용함
- ITM head가 매칭되지 않는 이미지-캡션 쌍을 제거함
- 논문에서는 새로운 학습 데이터셋을 아래의 수식으로 나타냄 \(D' = \{(I_w, T_w')\} \cup \{(I_w, T_s')\} \cup \{(I_h, T_h)\}\)
3. 주요 시사점 및 핵심 컨셉
- VLP(Vision-Language-Pre-training) 연구의 가장 기본이 되는 모델과 데이터 측면의 모든 부분에서 개선이 이루어짐
- 자기지도 + 자가검증
- 외부 라벨 없이 모델 스스로 데이터를 생성 및 검증
BLIP 논문은 앞으로 VLP 분야에서 모델 아키텍처와 데이터 부트스트레핑을 함께 고민하는 것이 기본이자 중요한 연구 방향임을 보여주는 논문이라 할 수 있음.
This post is licensed under CC BY 4.0 by the author.